
SG-NN: Sparse Generative Neural Networks for Self-Supervised Scene Completion of RGB-D Scans (CVPR'20)
Abstract
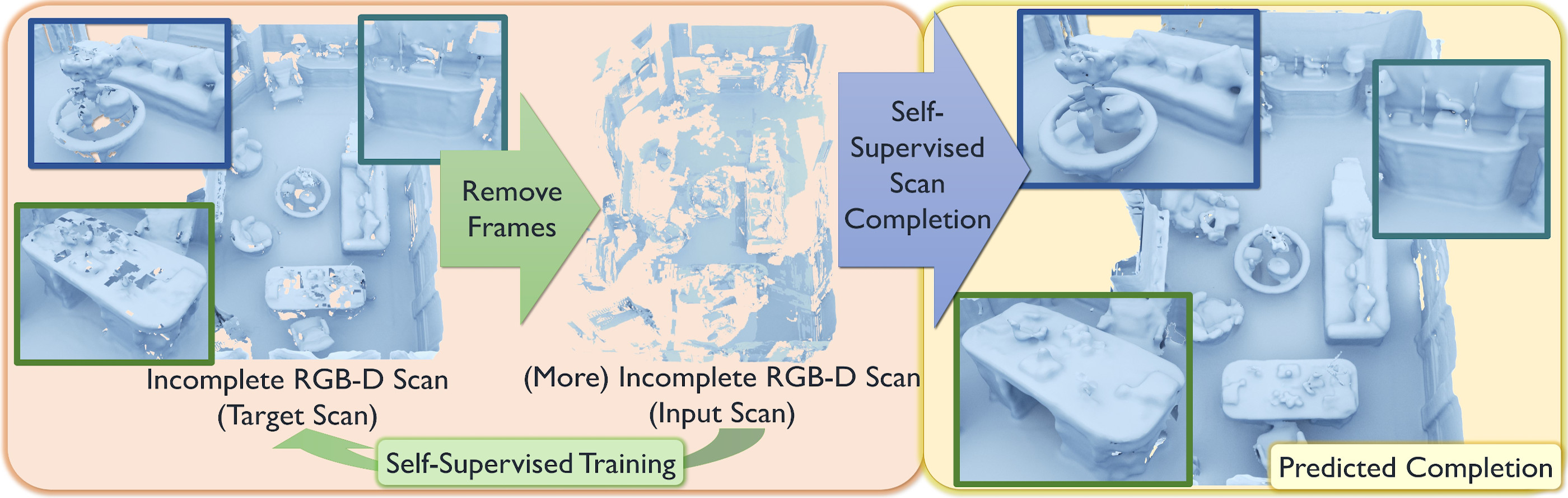
We present a novel approach that converts partial and noisy RGB-D scans into high-quality 3D scene reconstructions by inferring unobserved scene geometry.
Our approach is fully self-supervised and can hence be trained solely on real-world, incomplete scans.
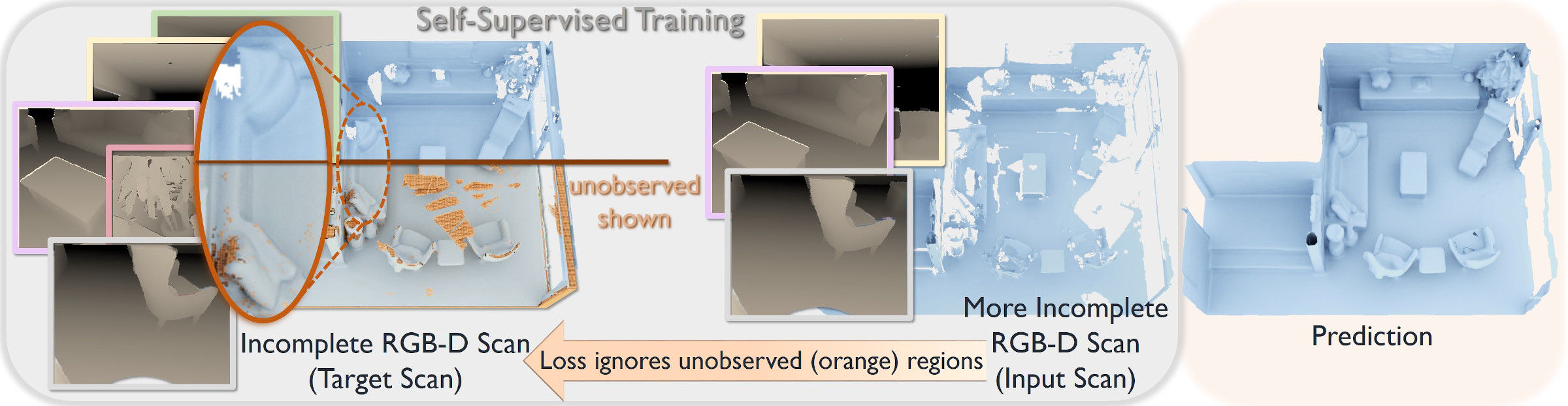
To achieve self-supervision, we remove frames from a given (incomplete) 3D scan in order to make it even more incomplete; self-supervision is then formulated by correlating the two levels of partialness of the same scan while masking out regions that have never been observed.
Through generalization across a large training set, we can then predict 3D scene completion without ever seeing any 3D scan of entirely complete geometry.
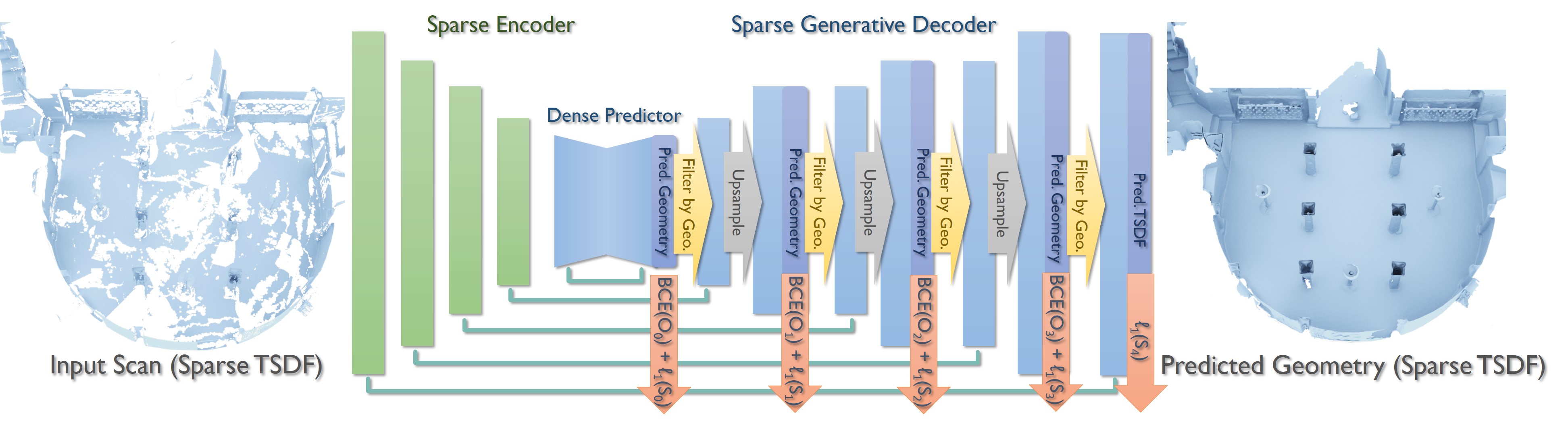
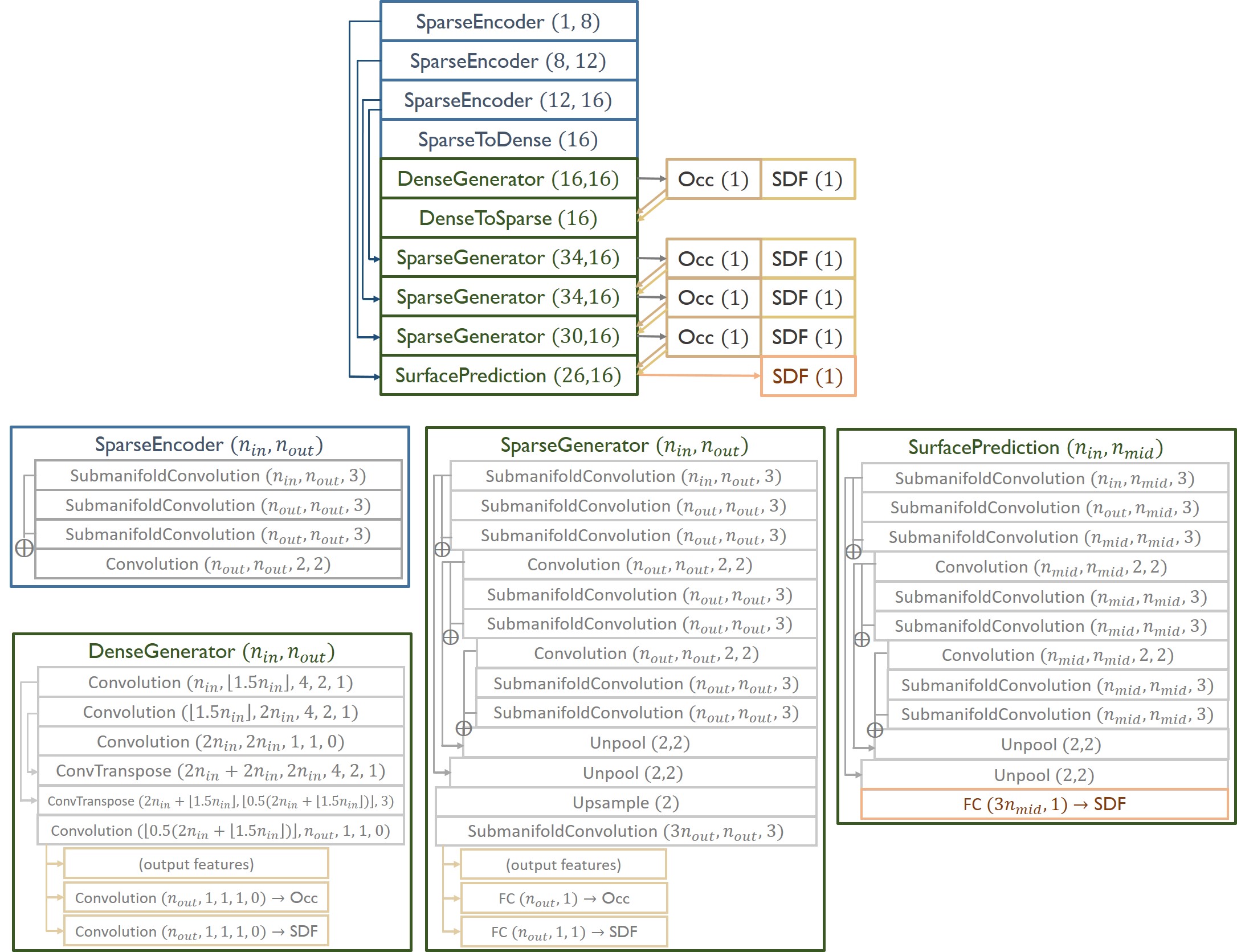
Combined with a new 3D sparse generative neural network architecture, our method is able to predict highly-detailed surfaces in a coarse-to-fine hierarchical fashion, generating 3D scenes at 2cm resolution, more than twice the resolution of existing state-of-the-art methods as well as outperforming them by a significant margin in reconstruction quality.
Video
Figures
Figures found in the paper. Click to enlarge and reveal the figure captions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Comparison to state-of-the-art scan completion approaches on Matterport3D [3] data (5cm resolution), with input scans generated from a subset of frames. In contrast to the fully-supervised 3D-EPN [11] and ScanComplete [12], our self-supervised approach produces more accurate, complete scene geometry.](/projects/sg-nn/figures/comparison_5cm.jpg){kind=link}
![Evaluating varying target data completeness available for training. We generate various incomplete versions of the Matterport3D [3] scans using ≈30%, 40%, 50%, 60%, and 100% (all) of the frames associated with each room scene, and evaluate on the 50% incomplete scans. Our self-supervised approach remains robust to the level of completeness of the target training data.](/projects/sg-nn/figures/incompleteness.jpg){kind=link}
![Scan completion results on Matterport3D [3] data (2cm resolution), with input scans generated from a subset of frames. Our self-supervision approach using loss masking enables more complete scene prediction than direct supervision using the target RGB-D scan, particularly in regions where occlusions commonly occur.](/projects/sg-nn/figures/comparison_2cm_selfsup.jpg){kind=link}
{kind=link}
Paper
