
Forecasting Characteristic 3D Poses of Human Actions (CVPR'22)
Abstract
We propose the task of forecasting characteristic 3D poses: from a short sequence observation of a person, predict a future 3d pose of that person in a likely action-defining, characteristic pose -- for instance, from observing a person picking up an apple, predict the pose of the person eating the apple.
Prior work on human motion prediction estimates future poses at fixed time intervals. Although easy to define, this frame-by-frame formulation confounds temporal and intentional aspects of human action. Instead, we define a semantically meaningful pose prediction task that decouples the predicted pose from time, taking inspiration from goal-directed behavior.
To predict characteristic poses, we propose a probabilistic approach that models the possible multi-modality in the distribution of likely characteristic poses. We then sample future pose hypotheses from the predicted distribution in an autoregressive fashion to model dependencies between joints.
To evaluate our method, we construct a dataset of manually annotated characteristic 3d poses. Our experiments with this dataset suggest that our proposed probabilistic approach outperforms state-of-the-art methods by 26% on average.
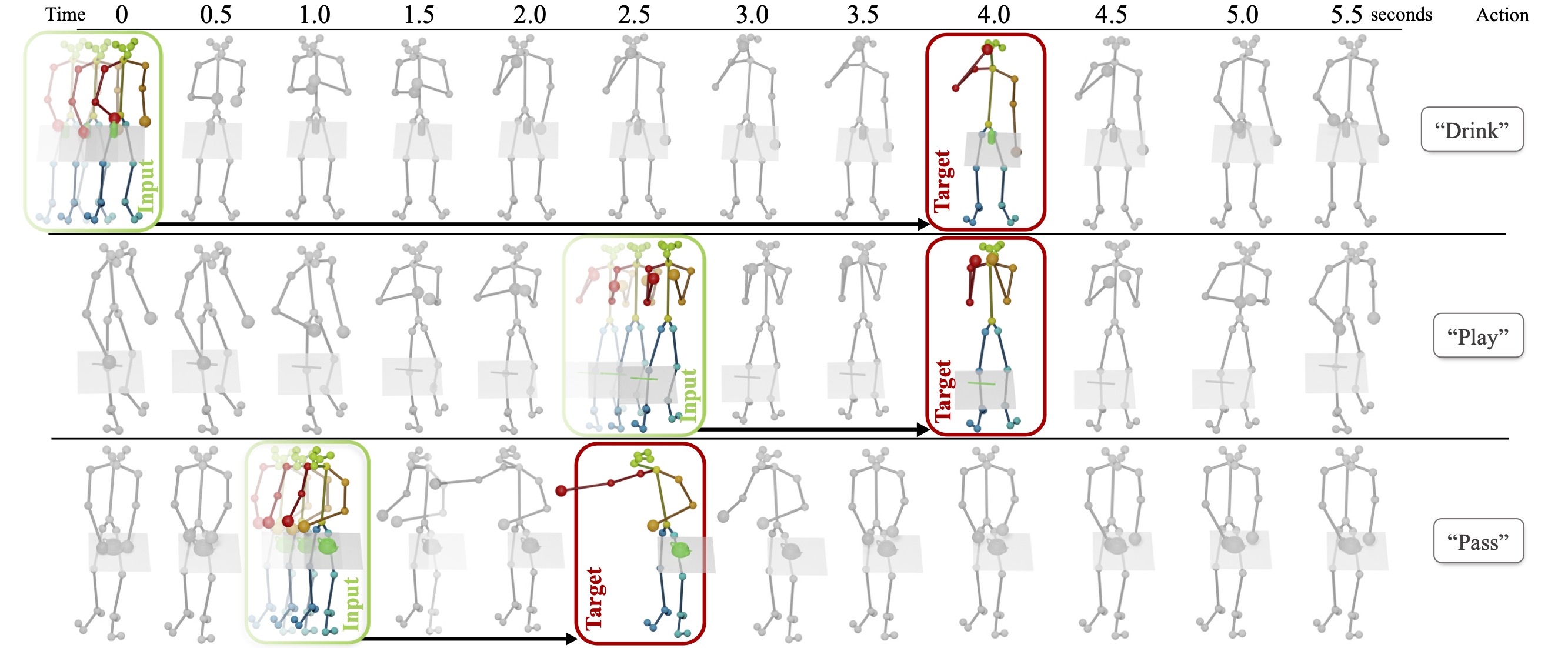
Teaser. For a real-world 3d skeleton sequence of a human performing an action, we propose to forecast the semantically meaningful characteristic 3d pose, representing the action goal for this sequence. As input, we take a short observation of a sequence of consecutive poses leading up to the target characteristic pose. Thus, we propose to take a goal-oriented approach, predicting the key moments characterizing future behavior, instead of predicting continuous motion, which can occur at varying speeds with predictions more easily diverging for longer-term (>1s) predictions. We develop an attention-driven probabilistic approach to capture the most likely modes of possible future characteristic poses.
Video
You can download a high-quality version of this video here.
Paper

Bibtex
If you find this work useful for your research, please consider citing:
@article{diller2022charposes,
title={Forecasting Characteristic 3D Poses of Human Actions},
author={Diller, Christian and Funkhouser, Thomas and Dai, Angela},
booktitle={Proc. Computer Vision and Pattern Recognition (CVPR), IEEE},
year={2022}
}