Projects
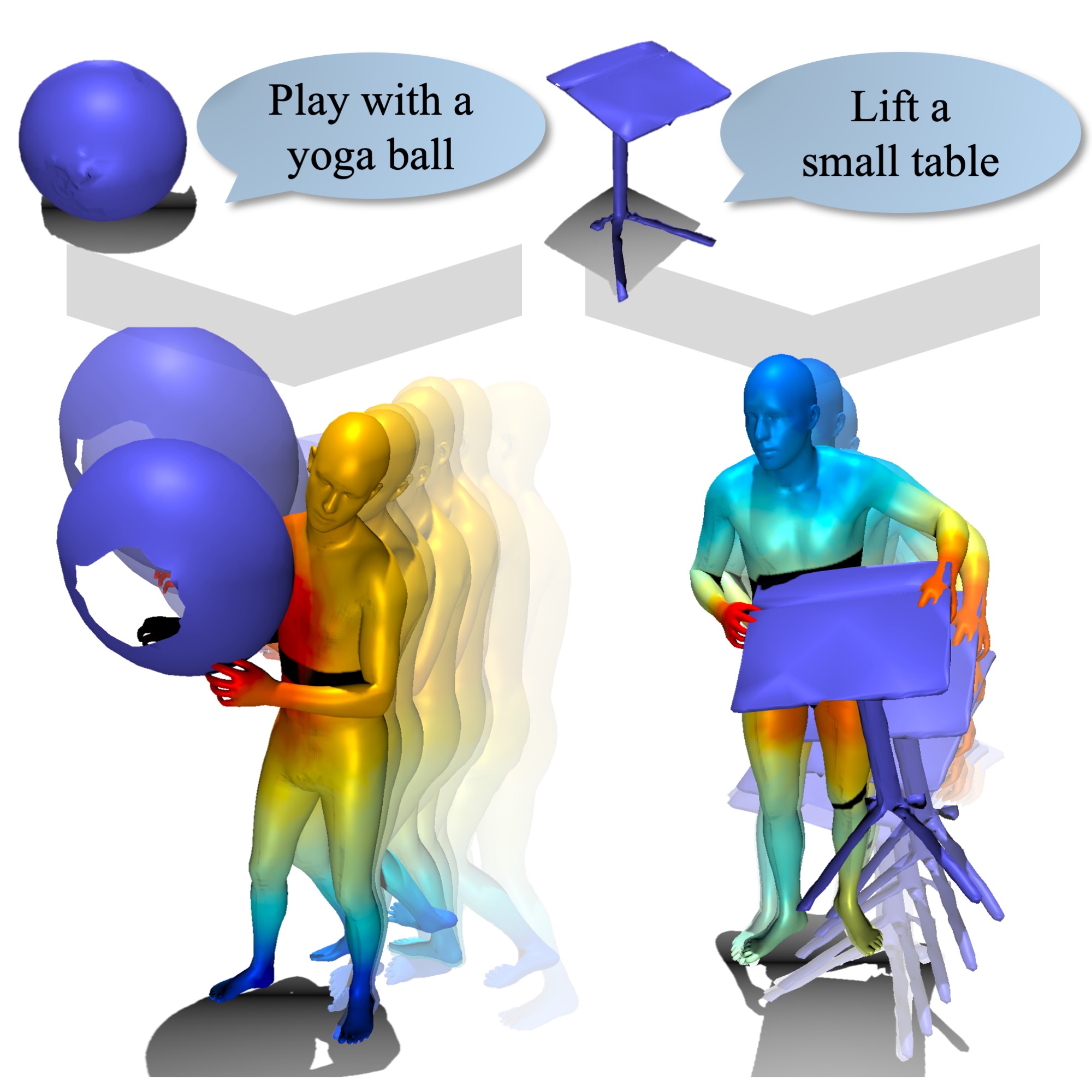
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation (CVPR'24)
We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text.
We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions.
Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to...
FutureHuman3D: Forecasting Complex Long-Term 3D Human Behavior from Video Observations (CVPR'24)
We present a generative approach to forecast long-term future human behavior in 3D, requiring only weak supervision from readily available 2D human action data. This is a fundamental task enabling many downstream applications.
The required ground-truth data is hard to capture in 3D (mocap suits, expensive setups) but easy to acquire in 2D (simple RGB cameras). Thus, we design our method to only require 2D RGB data while being able to generate 3D human motion sequences. We use a...
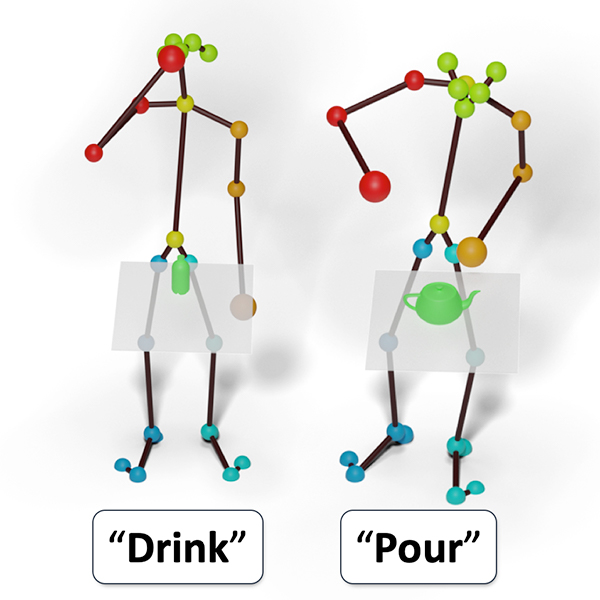
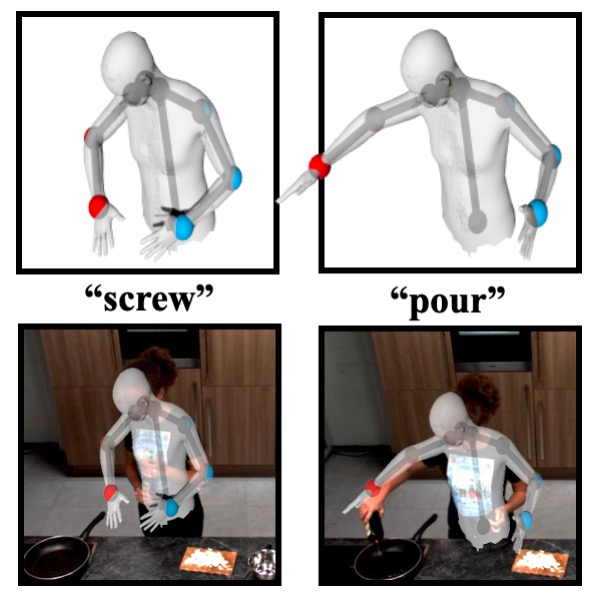
Forecasting Characteristic 3D Poses of Human Actions (CVPR'22)
We propose the task of forecasting characteristic 3D poses: from a short sequence observation of a person, predict a future 3d pose of that person in a likely action-defining, characteristic pose -- for instance, from observing a person picking up an apple, predict the pose of the person eating the apple.
Prior work on human motion prediction estimates future poses at fixed time intervals. Although easy to define, this frame-by-frame formulation confounds...

SG-NN: Sparse Generative Neural Networks for Self-Supervised Scene Completion of RGB-D Scans (CVPR'20)
We present a novel approach that converts partial and noisy RGB-D scans into high-quality 3D scene reconstructions by inferring unobserved scene geometry.
Our approach is fully self-supervised and can hence be trained solely on real-world, incomplete scans.
To achieve self-supervision, we remove frames from a given (incomplete) 3D scan in order to make it even more incomplete; self-supervision is then formulated by correlating the two levels of partialness of the...

3D Shape Completion from Sparse Point Clouds Using Deep Learning
We tackle the problem of generating dense representations from sparse and partial point clouds. We achieve this with a data-driven approach which learns to complete incoming sets of 3D points in a fully-supervised manner.
To this end, we first prepare a suitable dataset containing partial scans, each one correlated with complete ground-truth representations. We base this on the widely used ModelNet40 dataset which features high-quality CAD scans of 40 different object categories. ...
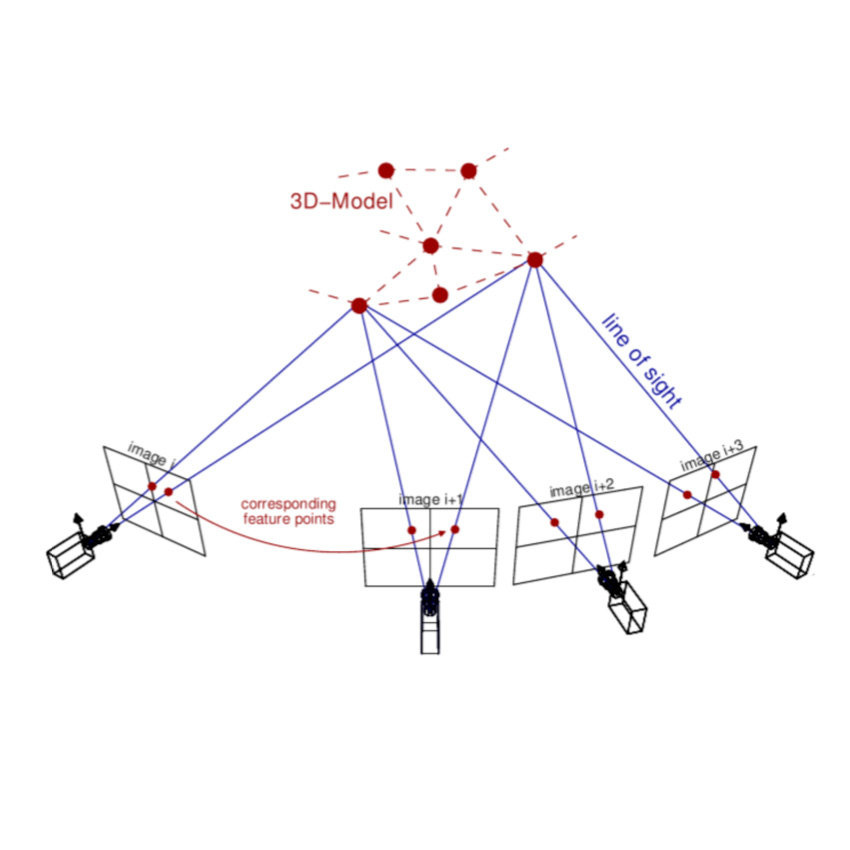
BundleACeres - Structure from Motion using Bundle Adjustment with the Ceres Solver
An implementation of Bundle Adjustment with the Ceres Solver as optimizer.
It matches a chain of incoming RGB images using ORB keypoints and BRISK descriptors in order to find 3D points.
The Ceres Solver is then used to jointly solve for the locations of 3D points and camera poses of the frames.
It is implemented in modern C++14 and utilizes OpenCV 3, Ceres, PCL and others.

KinectFusionLib - Modern Implementation of the KinectFusion Approach
Implementation of the KinectFusion approach to generating three-dimensional models from depth image scans.
Here, the original method has been extended with the MarchingCubes algorithm to allow exporting the model as a dense surface mesh.
Realized in modern C++14 and CUDA to allow real-time reconstruction.
Developed in the context of an interdisciplinary project in cooperation with the Chair for Computer Aided Medical Procedures and Augmented Reality and Dynamify GmbH.

VideoMagnification - Magnify motions and detect heartbeats
This application allows the user to magnify motion and detect heartbeats from videos and webcam video streams.
It is an implementation of Wu, Hao-Yu, et al.: “Eulerian video magnification for revealing subtle changes in the world”. You can find out more about motion magnification on the project homepage.
My implementation can be found here. It makes use of modern C++11, the open-source vision library OpenCV 3.1 and the UI framework QT 5.
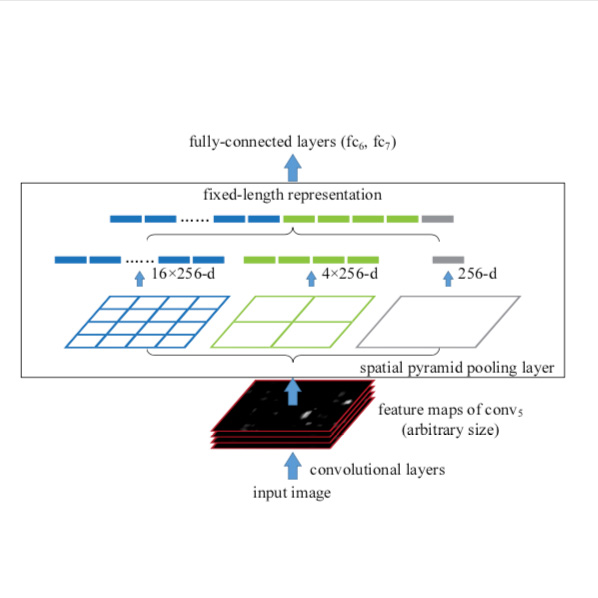
Spatial Pyramid Pooling as an additional layer in caffe
An implementation of the concept proposed in He, Kaiming, et al. “Spatial pyramid pooling in deep convolutional networks for visual recognition“.
It adds a new custom layer to the AlexNet architecture which performs spatial pyramid pooling in order to remove the network’s need for fixed-size input images.
This was part of my Bachelor’s Thesis which I wrote at the Multimedia Computing and Computer Vision Lab, University of Augsburg under the supervision of...